Distributed and Parallel Information Retrieval
Providing timely access to text collections both locally and across
the Internet is instrumental in making information retrieval (IR)
systems truly useful. In order to users to effectively access these
collections, IR systems must provide coordinated, concurrent, and
distributed access. We investigate different architectures for
distributed and parallel information retrieval in order to provide
efficient and scalable IR services. In particular, we use partial
collection replication.
Performance of Distributed Information Retrieval Architectures
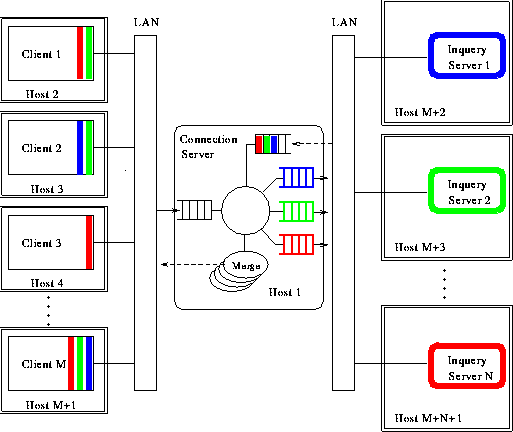
We developed a prototype distributed information retrieval system
which allows multiple users to search multiple document collections
concurrently. The Distributed Information Retrieval Architecture consists of a
set of clients (users) that connect to a set of IR systems via a
connection server. The connection server is responsible for all
messages sent between the clients and the IR systems. Since it is
difficult to test the performance of large distributed systems, we
created a simulation model of the distributed system in order to
analyze the performance of the system under a variety of conditions.
Furthermore, we are able to easily change the architecture and
evaluate the effectiveness of the change. Our results show that our
architecture is able to handle a large number of clients and text
collections by using a surprisingly small number of connection
servers.
Parallel Information Retrieval Servers
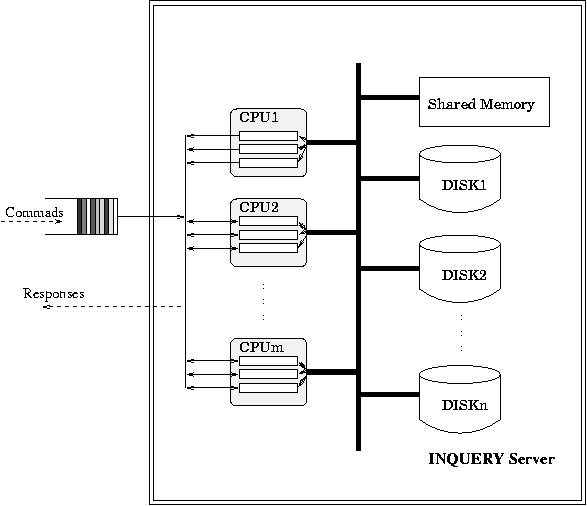
We have also developed a Parallel IR Server to investigate how best to
exploit a symmetric multiprocessors when building high performance IR
servers. Although it is possible to create systems with lots of CPU
and disk resources, the important questions are how much of
which hardware and what software structure is needed to
effectively exploit hardware resources. In some cases, adding
hardware degrades performance rather than improves it. We also
compare the performance of a multi-threaded IR server to a multitasking
IR server. As expected, the multi-threaded server is faster, but the
multitasking server is competitive. Thus, for a large legacy system,
it may not be worth the effort to convert a single threaded system
into a multi-threaded system.
Replicating Information Retrieval Collections
Distributing excessive workloads and searching as little data as
possible while maintaining acceptable retrieval accuracy are two ways
to improve performance and scalability of a distributed IR
system. Replication and partial replication of a collection serves
these two purposes. Replicating collections on multiple servers can
distribute excessive workloads posed on a single server; replicating
collections on servers that are closer to their users can improve
performance by reducing network traffic and minimizing network
latency. We investigate how to build and rank partial replicas in a
information retrieval system. We build a
hierarchy of replicas based on query frequency
and available resources (the number of servers and their size).
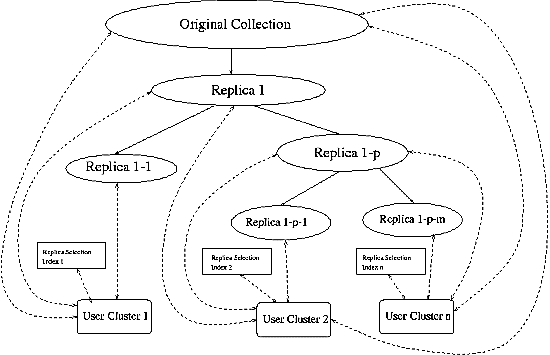
Here we give an example to show how this architecture works. When a
user in the user cluster 1 issues a query, the query goes to replica
selection index 1 to determine relevance of Replica 1-1,
Replica 1, and the original collection. If Replica
1-1 is ranked as the top one, query may go to any of Replica
1-1, Replica 1, and the original collection for
processing, based on server load and network traffic. If Replica
1 is ranked as the top one, query may go to either Replica
1 or the original collection. Otherwise the query only goes to
the original collection.
Query Locality
In our work, we examine queries from real system logs and show that
there is sufficient query locality in real systems to justify partial
collection replication. We use 40 days of queries from THOMAS, the
Library of Congress, and one day of Excite logs to study locality
patterns in real systems. We find there is sufficient query locality
that remains high over long periods of time which will enable partial
replication to maintain effectiveness and significantly improve
performance. For THOMAS, updating replicas hourly or even daily is
unnecessary. However, we need to some mechanism to deal with bursty
events. We propose two simple updating strategies that trigger
updates based on events and performance, instead of regular updating.
In our traces, query exact match misses many overlaps between queries
with different terms that in fact return the same top documents,
whereas partial replication with an effective replica selection
function will find the similarities. We believe this trend will hold
for other query sets against text collections and for web queries.
Finding the Appropriate Replica
We extend the inference network model to rank and select partial
replicas. We compare our new replica selection function to previous
work on collection selection over a range of tuning parameters. For a
given query, our replica selection algorithm correctly determines the
most relevant of the replicas or original collection, and thus
maintains the highest retrieval effectiveness while searching the
least data as compared with the other ranking functions. Simulation
results show that with load balancing, partial replication
consistently improves performance over collection partitioning on
multiple disks of a shared-memory multiprocessor and it requires only
modest query locality.
Searching a Terabyte of Text
We use our architecture to investigate how to search a terabyte of
text using partial replication. We build a hierarchy of replicas
based on query frequency and available resources, and use the InQuery
retrieval system for the replicas and the original text database. We
demonstrate the performance of our system searching a terabyte of text
using a validated simulator. We compare the performance of partial
replication with partitioning over additional servers. Our results
show that partial replication is more effective at reducing execution
times than partitioning on significantly fewer resources. For example,
using 1 or 2 additional servers for replica(s) achieves similar or
better performance than partitioning over 32 additional servers, even
when the largest replica satisfies only 20% of commands. Higher query
locality further widens the performance differences. Our work porting
and validating InQuery and the simulator from a slower processor to
the Alpha, as well as experiments with faster querying times which are
reported elsewhere, lead us to believe the performance trends will
hold for faster systems using fewer resources.
Participants
Papers
Acknowledgements
This work is supported by grants from Digital Equipment, NSF grant
EIA-9726401, and an NSF Infrastructure grant CDA-9502639, Library of
Congress and Department of Commerce under cooperative agreement number
EEC-9209623, and by the Defense Advanced Research Projects Agency/ITO
under ARPA order number D468, issued by ESC/AXS contract number
F19628-95-C-0235. Kathryn S. McKinley is supported by an NSF CAREER
Award CCR-9624209. Any opinions, findings, and conclusions or
recommendations expressed in this material are those of the author(s)
and do not necessarily reflect the views of the sponsors.
Return to ALI home page.
(Last changed: April 3, 1998.)